Büyük ölçekli analitik ve data lakehouse mimarileri için verileri doğrudan Azure Data Lake Storage Gen2'ye (ADLS Gen2) aktarın.
Bağlayıcı aşağıdakileri destekler:
- Akıllı Gruplama (Smart Batching): Verimli dosya boyutları için verileri bellekte tamponlayın.
- Dinamik Bölümleme: Zaman, cihaz, bölge veya konuya dayalı esnek dizin yapıları.
- Parquet Formatı: Analitik iş yükleri (Synapse, Databricks, Spark) için optimize edilmiş sütunsal depolama.
ADLS Gen2 Dokümantasyonu
learn.microsoft.com/azure/storage/blobs/data-lake-storage-introduction
Azure Kurulum Rehberi
Bu bağlayıcıyı kullanmak için, Azure kaynaklarını Proxus'un veri yazmasına izin verecek şekilde yapılandırmanız gerekir.
Depolama Hesabı (Storage Account) Oluşturun
- Azure Portal'a gidin.
- Yeni bir Storage Account oluşturun.
- Advanced sekmesi altında, Hierarchical namespace özelliğini etkinleştirin. Bu, ADLS Gen2 için gereklidir.
- Account Name'i not edin.
Konteyner (Container) Oluşturun
- Yeni Depolama Hesabınıza gidin.
- Data storage > Containers'a gidin.
- Yeni bir konteyner oluşturun (örn.
telemetry). Bu sizin FileSystem parametreniz olacaktır.
Bir Uygulama Kaydedin (Service Principal)
- Microsoft Entra ID (eski adıyla Azure AD) araması yapın.
- App registrations > New registration'a gidin.
- İsimlendirin (örn. "Proxus-Integration") ve kaydedin.
- Genel Bakış sayfasından, Application (client) ID ve Directory (tenant) ID değerlerini kopyalayın.
İstemci Gizli Anahtarı (Client Secret) Oluşturun
- Uygulama Kaydınızda, Certificates & secrets'a gidin.
- New client secret oluşturun.
- Value değerini hemen kopyalayın (daha sonra göremezsiniz). Bu sizin ClientSecret'ınızdır.
İzinleri Atayın (RBAC)
- Storage Account'unuza geri dönün.
- Access Control (IAM) > Add > Add role assignment seçin.
- Storage Blob Data Contributor rolünü seçin (Not: "Contributor" veya "Owner" veri erişimi için YETERLİ DEĞİLDİR).
- Erişimi User, group, or service principal'a atayın.
- Adım 3'te kaydettiğiniz Uygulamayı seçin.
Konfigürasyon Parametreleri
Proxus Yönetim Konsolu'nda bağlayıcıyı yapılandırmak için Integrations > Outbound Connectors'a gidin ve yeni bir Azure Data Lake hedefi oluşturun.
Konfigürasyon penceresini açmak için Edit Parameters butonuna tıklayın.
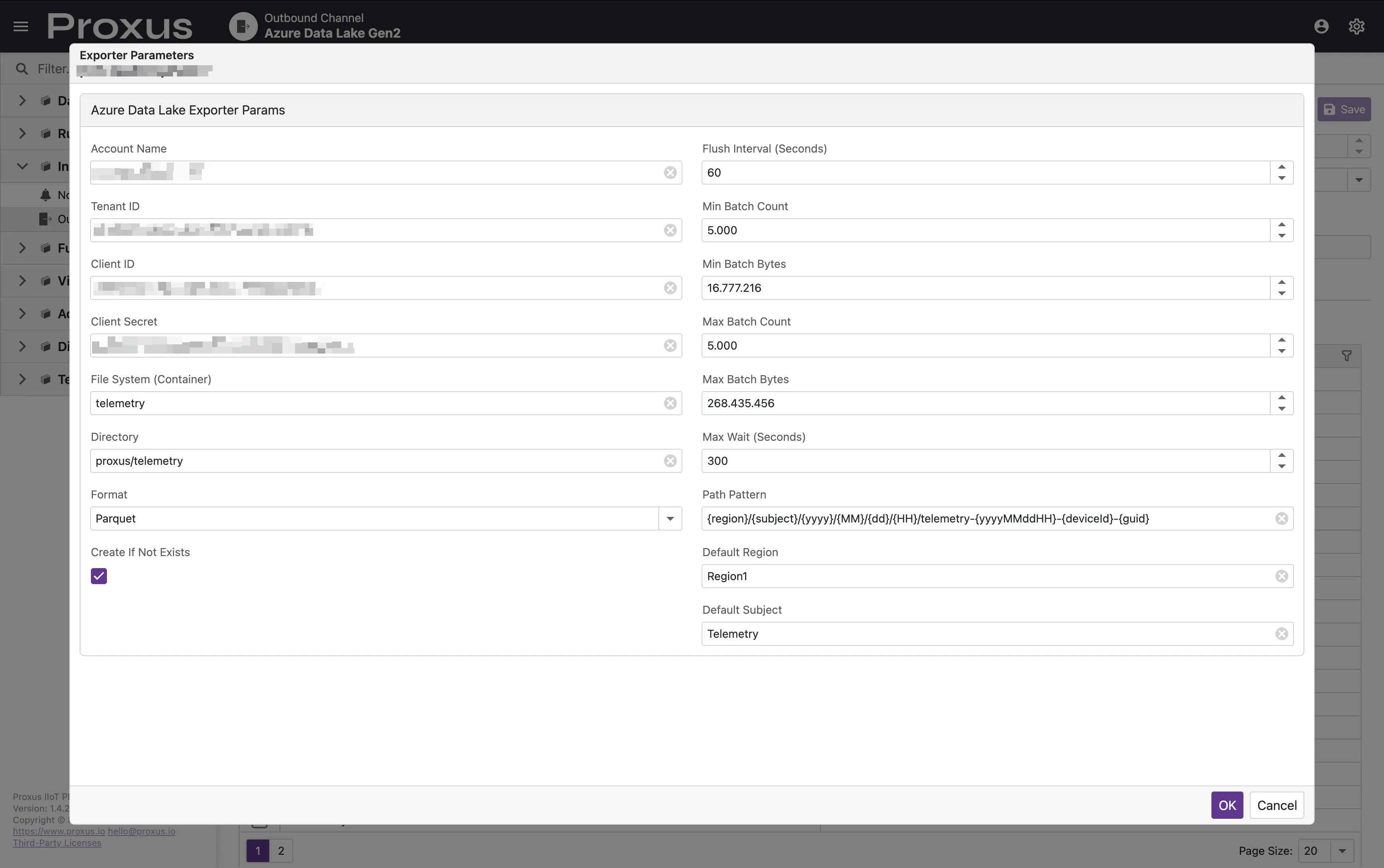
Kimlik Doğrulama
Kimlik doğrulama bir Service Principal üzerinden yönetilir.
| Parametre | Zorunlu | Tip | Varsayılan | Açıklama |
|---|---|---|---|---|
| AccountName | Evet | string | - | Azure Storage Account adı. |
| TenantId | Evet | string | - | Azure Tenant ID. |
| ClientId | Evet | string | - | Service Principal için Application (Client) ID. |
| ClientSecret | Evet | string | - | Service Principal için Client Secret. |
Depolama Ayarları
| Parametre | Zorunlu | Tip | Varsayılan | Açıklama |
|---|---|---|---|---|
| FileSystem | Evet | string | - | Konteynerin (filesystem) adı. |
| Directory | Hayır | string | / | Konteyner içindeki temel dizin yolu. |
| Format | Hayır | string | parquet | Dışa aktarım formatı: parquet, json, veya csv. |
| PathPattern | Hayır | string | Aşağıya bakın | Oluşturulan dosyalar için dinamik yol şablonu. |
| CreateIfNotExists | Hayır | bool | true | Mevcut değilse konteyner/dizin oluşturun. |
| CsvDelimiter | Hayır | string | , | Format csv olarak ayarlandığında kullanılan ayırıcı. |
Toplu İşlem & Performans
Bu ayarlar, verilerin dahili tampondan Azure'a ne zaman aktarılacağını (flush) kontrol eder.
| Parametre | Tip | Varsayılan | Açıklama |
|---|---|---|---|
| FlushIntervalSeconds | int | 30 | Toplu işlem eşiklerini kontrol etme aralığı. |
| MaxWaitSeconds | int | 300 | Bir partiyi (batch) aktarmadan önce açık tutmak için maksimum süre. |
| MinBatchCount | int | 5000 | MaxWaitSeconds sonrasında bir aktarımı tetiklemek için gereken minimum kayıt sayısı. |
| MinBatchBytes | long | 16777216 | MaxWaitSeconds sonrasında bir aktarımı tetiklemek için gereken minimum bayt (16MB). |
| MaxBatchCount | int | 100000 | Anında aktarımı zorlamak için kayıt sayısı üst sınırı. |
| MaxBatchBytes | int | 67108864 | Anında aktarımı zorlamak için parti boyutu üst sınırı (64MB). |
Performans Değerlendirmeleri
"Küçük Dosya Problemi"nden Kaçınma
Büyük veri ekosistemlerinde, milyonlarca küçük dosyaya (örneğin her biri birkaç KB veya MB) sahip olmak, Apache Spark, Azure Databricks veya Azure Synapse gibi analitik motorlarının performansını önemli ölçüde düşürür. Bu "Küçük Dosya Problemi" (Small File Problem) olarak bilinir.
Bundan kaçınmak için şunları öneriyoruz:
- Toplu İşlem Eşiklerini Artırın: Daha büyük dosyalar oluşturmak için
MaxBatchBytesveMaxBatchCountdeğerlerini ayarlayın. Parquet dosyaları büyük veri araçları için ideal olarak 128MB - 512MB olsa da, dosya başına 32MB - 64MB'a ulaşmak bile sık sık yapılan küçük aktarımlara göre büyük bir gelişmedir. - Bekleme Sürelerini Ayarlayın: Veri hacminiz düşükse, Proxus'un yeni bir dosya oluşturmadan önce daha fazla veri toplamasına izin vermek için
MaxWaitSecondsdeğerini artırın (örneğin 30 dakika için 1800 yapın). - Optimize Edilmiş Yol Şablonları: Dizin yapınızın ortasında, çok fazla bölümlenmeye (partitioning) neden oluyorsa çok fazla yüksek kardinaliteli dinamik token (örneğin
{guid}veya{deviceId}) kullanmaktan kaçının.
Yol Şablonu Tokenları
PathPattern parametresi çalışma zamanında değiştirilen dinamik tokenları destekler:
| Token | Açıklama |
|---|---|
{region} | Region veya DefaultRegion meta verisinden alınan değer. |
{subject} | Subject veya DefaultSubject meta verisinden alınan değer. |
{yyyy} | Yıl (4 haneli). |
{MM} | Ay (01-12). |
{dd} | Gün (01-31). |
{HH} | Saat (00-23). |
{yyyyMMddHH} | Birleşik zaman damgası (örn. 2024011614). |
{deviceId} | Cihazın benzersiz kimliği. |
{deviceName} | Cihazın adı. |
{guid} | Dosya adı çakışmalarını önlemek için benzersiz bir tanımlayıcı. |
Varsayılan Şablon: {region}/{subject}/{yyyy}/{MM}/{dd}/{HH}/telemetry-{yyyyMMddHH}-{deviceName}-{guid}
İç Davranış
- Güvenilirlik: Dayanıklı bir outbox mekanizması kullanır. Mesajlar yalnızca Azure'a başarılı bir yüklemeden sonra onaylanır (ACK). Yükleme başarısız olursa, mesajlar olumsuz onaylanır (NAK) ve yeniden denenir.
- Bellek Yönetimi: Yüksek hacimli dışa aktarımlar sırasında Large Object Heap (LOH) parçalanmasını önlemek için gelişmiş bellek havuzlama (
RecyclableMemoryStream) kullanır. - Parquet Şeması:
parquetformatı kullanıldığında, dosyalardeviceId,deviceName,topic,measureName,measureValueTypevedouble,long,bool,stringtürleri için değerler ile birlikte birtimestampiçeren kesin olarak yazılmış bir şema ile yazılır.