Nov 11, 2025 · 9 min read
Methodology notes
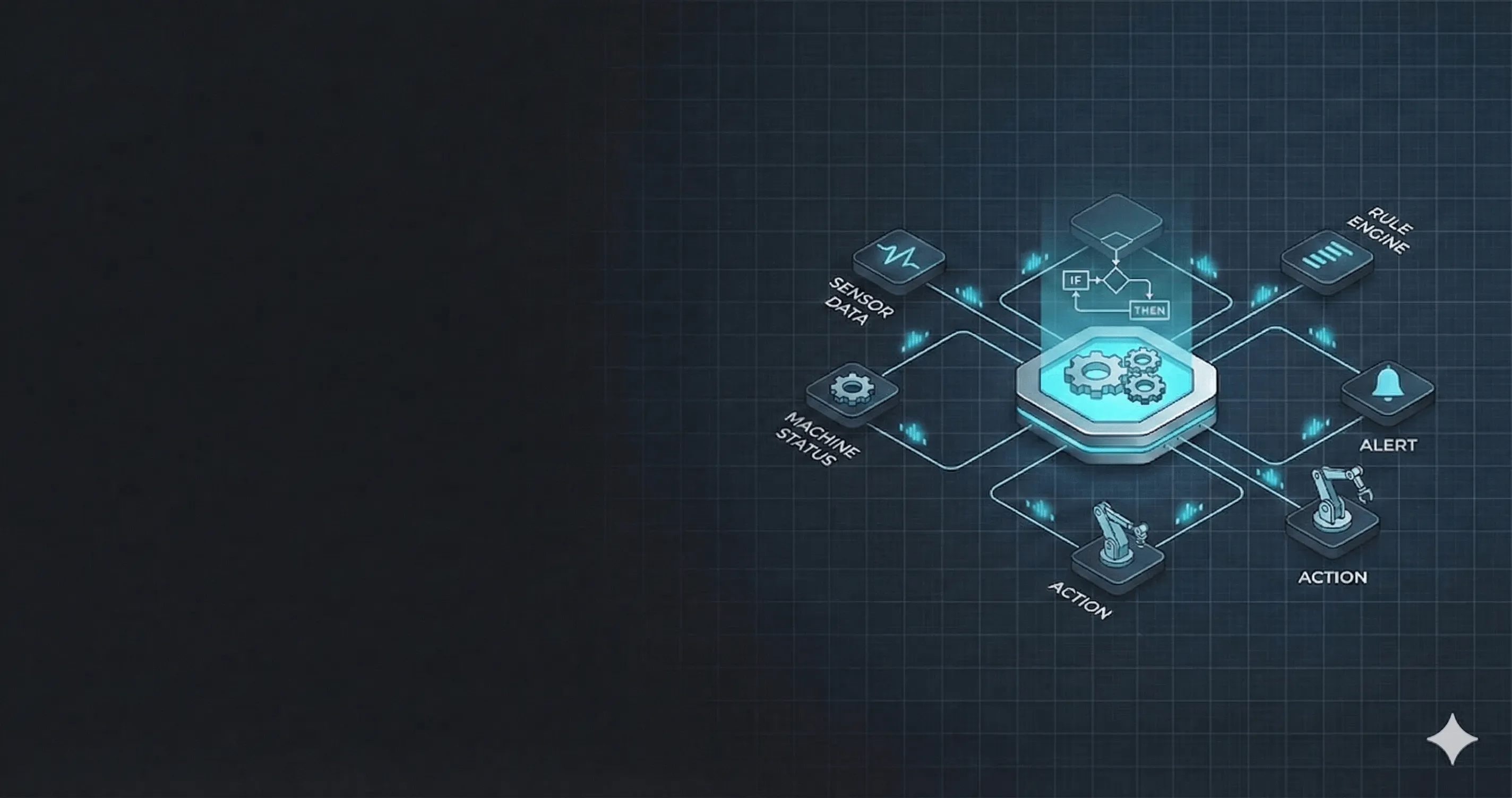
Designing a Rule Engine for Industrial Automation
Master industrial rule engines: from simple alerts to complex multi-device workflows. Learn how Proxus combines visual rules with C# scripting to handle high-volume rule evaluation with optimized performance.
- Evidence level: Medium (field observations + public standards; not a universal benchmark).
- Measurement scope: Performance and economic outcomes vary by hardware, topology, workload shape, sampling profile, and process constraints.
- Primary references: IEC 62443-2-1, ISA-95 / IEC 62264, NIST SP 800-82r3.
- Implementation docs: Edge Architecture and Unified Namespace.
Designing a Rule Engine That Scales with Your Factory
Industrial rule engines usually begin with a straightforward requirement:
"Send an alarm if this tag exceeds that value."
The problem is that real plants rarely stop there. Within a short period, teams usually need duration checks, shift-aware conditions, context overrides, cross-device correlation, ERP/CMMS actions, and safe rollout of logic changes. A rule engine that works for a pilot can become hard to operate once these requirements accumulate.
This article focuses on the design choices behind a production-facing industrial rule engine: authoring model, execution model, validation workflow, and operational safety boundaries. The exact throughput and latency you can achieve depend on workload shape, rule complexity, hardware, and whether the evaluation path stays local or depends on external systems.
Outcomes depend on workload profile, hardware capacity, and deployment topology.
The Problem with Traditional Rule Engines
Rule engines become difficult when the problem is no longer a single threshold.
Challenge #1: Scope Growth
A simple alarm often becomes a stateful policy:
- alert only if the condition persists for a duration
- suppress the alarm during setup or maintenance windows
- escalate immediately when a harder limit is crossed
Challenge #2: Cross-Device Context
Many industrial decisions depend on more than one signal. "Machine A is warm" is not enough; the logic may also need line state, upstream availability, downstream congestion, or work-order context from a business system.
Challenge #3: Load and Determinism
As device count and rule count increase, the cost of polling, re-checking shared state, and calling external systems grows quickly. A design that relies on frequent database queries or broad recomputation will usually degrade under bursty telemetry.
Challenge #4: Change Management
Production logic needs a lifecycle. Teams typically need draft rules, staged validation, promotion to specific gateways, and a clear rollback path if false positives or unintended writes appear.
The Proxus Approach: Visual + Code Unified
Proxus addresses these problems with two authoring modes that target the same operational runtime.
Visual Criteria Builder (No-Code)
Visual rules are useful when the logic is explicit, bounded, and easy to review:
- threshold alarms
- shift-based notifications
- simple conditional writes
- basic routing to MQTT, webhooks, or ticketing systems
The advantage is not just accessibility. A visual rule is also easier for operations, controls, and software teams to review together before it is promoted.
C# Scripting for Advanced Cases
Some cases genuinely need code:
- multi-device correlation over a time window
- derived state calculations
- statistical smoothing or anomaly scoring
- transformations that are awkward to express as nested visual conditions
The important design principle is not "code everywhere." It is using scripting only where the visual model becomes harder to reason about than the logic itself.
Example Decision Pattern
Whether the logic is authored visually or in code, the decision path should still read like an operating policy:
IF temperature exceeds the warning threshold
AND the machine is in production mode
AND the condition persists for the configured duration
AND the line is not in a scheduled maintenance window
THEN publish an event, notify operations, and optionally create a maintenance taskThat policy is easier to validate than exposing internal runtime objects or SDK-specific implementation details in public content.
A Single Unified Execution Model
The main architectural value of a shared runtime is operational consistency. Teams should not have to learn one deployment model for visual rules and a different one for scripted rules.
In practice, scalability depends on a few factors:
- how often the triggering tags change
- whether the rule works from local in-memory state or needs external I/O
- whether the rule is per-device, cross-line, or cross-site
- whether the output is a local event, a broker publish, or a remote API call
Rules that stay local and evaluate against already-contextualized telemetry will usually perform better and more predictably than rules that depend on synchronous remote systems.
The implementation goal is therefore straightforward:
- keep the critical evaluation path local
- publish state changes rather than repeatedly poll for them
- separate live decisioning from heavier historical analytics
- isolate expensive integrations so they do not block the core rule loop
Validation, Rollout, and Safety Boundaries
The operational model matters as much as the rule syntax.
Validation Workflow
A practical industrial workflow usually includes:
- author the rule centrally
- run it against test or shadow data
- review alert quality and false positives
- promote it to selected gateways
- keep a rollback path to the previously approved version
This is especially important for rules that generate maintenance work orders or trigger write-capable downstream actions.
Safety Boundaries
Even a well-designed rule engine should not absorb every kind of industrial logic.
- Safety PLC logic remains in the safety layer.
- Hard real-time interlocks remain in deterministic control layers.
- Enterprise-facing orchestration, condition monitoring, and alerting are better candidates for a gateway rule engine.
Security Boundaries
If scripting is supported, it should operate under controlled execution boundaries, explicit review, and bounded permissions. Public marketing content does not need to expose internal class names or runtime limits to explain this; the important point is that user-authored logic should be reviewable, testable, and constrained.
When Complex Rule Engines May Be Overkill
In my experience, rule engines are sometimes overengineered for the problem at hand. Consider deploying simpler architectures in these scenarios:
- Hard Real-Time Safety Control: A safety-critical Emergency Stop or hardwired interlock should not rely on a rule engine, however robust. These decisions must remain in certified Safety PLCs hardwired with no software dependencies.
- Simple PLC-Resident Logic: If your automation needs are adequately served by native PLC logic (Boolean conditions, timers, counters), adding a rule engine introduces unnecessary operational complexity and maintenance burden.
- Single-Asset, Single-Criteria Plants: Factories with 3-5 simple threshold alarms may not justify the administrative overhead of a full rule engine platform. A basic SCADA alarm may suffice.
- Immature or Unstable Data Sources: If your tags are not consistently available, naming conventions are chaotic, or data quality is poor, a rule engine will amplify frustration rather than solve it. Stabilize your UNS first.
When this may not be suitable
- Lower-frequency telemetry may not justify full distributed complexity.
- Small single-line plants may prefer simpler architectures first.
- Strict legacy constraints may require phased adoption.
- Safety-critical closed-loop control should remain in PLC/Safety PLC layers.
Results vary with workload, hardware, and topology.
Frequently Asked Questions
When should I use the Visual Rule Builder vs. C# scripting?
Use the visual builder for 80% of rules: simple threshold alarms, notifications, basic conditional writes, and scheduled triggers. These are rules where the logic can be expressed as IF-THEN without complex state tracking. Drop to C# when you need: multi-device correlation across different PLCs, stateful computations (running averages, rate-of-change over windows), calls to external HTTP APIs, or integration with machine learning models. Many teams start visual and selectively migrate individual branches to C# as requirements grow - the unified runtime makes this seamless.
What latency can I expect from edge rule evaluation?
Latency depends primarily on how much data the rule touches and whether the execution path stays local. A simple gateway-local threshold or duration rule can evaluate quickly, while a rule that waits on an external HTTP endpoint will inherit network latency and downstream system variability. Safety-critical rules such as emergency stops should remain in deterministic PLC or Safety PLC layers; gateway rules are better suited to monitoring, orchestration, and enterprise-facing actions.
How do I test rules without affecting production?
Proxus supports staged deployment: deploy rule version v2 to a Test Gateway running with live shadow data (subscribed to the same MQTT topics as production, but with actions disabled or routed to a test namespace). Monitor v2 for a defined period (typically 3–7 days). Only after validation do you promote it to production gateways. This approach prevents false alarms and unintended writes.
Can rules trigger on OPC UA data sources?
Yes. The rule engine operates on tags within the Unified Namespace, regardless of their original source protocol. If an OPC UA tag is mapped to the UNS via the Proxus Edge Gateway, it becomes a first-class trigger just like Modbus, S7, or native MQTT tags. The rule does not know or care about the upstream protocol.
How do rules synchronize across multiple Edge Gateways?
Rules are authored centrally on the Proxus Platform and deployed to specific Edge Gateways. Each gateway evaluates rules independently against its local tag set - there is no distributed consensus protocol, which is deliberate: it prevents network-dependent latency on safety-critical decisions. For cross-site correlation (e.g., comparing OEE across plants), use central rules that subscribe to aggregated UNS topics published by each gateway.
Conclusion: Rules as Production Assets
In Proxus, automation rules are not an afterthought bolted onto a visualization tool. They are first-class engineering assets: versioned, sandboxed, tracked, and often optimized.
Whether you need a simple email alert or a complex machine-learning orchestration script, the unified visual/code engine scales from single-use cases to mission-critical, high-frequency automation.
References
- IEC 61131-3 - International standard for PLC programming languages, defining structured text (ST) and function block diagram (FBD) patterns that inspired industrial rule engine design. IEC 61131
- Charles Forgy, "Rete: A Fast Algorithm for the Many Pattern/Many Object Pattern Match Problem" (1982) - The foundational algorithm behind many production rule systems, relevant to understanding rule evaluation performance.
- Carl Hewitt, "A Universal Modular Actor Formalism for Artificial Intelligence" (1973) - The mathematical foundation of the Actor Model used as the Proxus rule execution runtime.
- OPC Foundation - OPC UA Alarms & Conditions - Specification for industrial alarm management via OPC UA, relevant as a data source for rule engine triggers. opcfoundation.org
Explore how the Proxus Rule Engine integrates with your existing architecture by reading our Edge Computing Patterns guide, or see how rules drive IT/OT convergence and predictive maintenance workflows.